
Die Grenzen dieser Vorgehensweise sind seit langem bekannt: Menschliche Prüfer bewerten Fehler nie völlig objektiv. Faktoren wie Tagesform, Erfahrung, individuelle Wahrnehmung oder schlicht Ermüdung beeinflussen die Ergebnisse. So bleiben fehlerhafte Teile unentdeckt und gelangen weiter in den Prozess oder zum Kunden (Schlupf), während gleichzeitig einwandfreie Teile fälschlich aussortiert werden (Pseudoausschuss). Dieser Status quo befindet sich jedoch im Wandel. 80% der Befragten äußern den Wunsch, die manuellen Aspekte der Qualitätskontrolle zu automatisieren. KI-basierte Systeme erreichen Prüfgenauigkeiten auf dem Niveau stets aufmerksamer menschlicher Prüfer – und das ohne Ermüdung oder Schwankungen. Dennoch setzen bislang nur 19% der Unternehmen entsprechende Systeme ein. Dies zeigt: Mit KI-Systemen verfügen wir bereits über eine Lösung, die viele der manuellen Kontrollen automatisieren kann. In der Praxis scheitern jedoch viele Unternehmen an den Hürden der Implementierung.
Datenqualität
KI-Inspektionssysteme erreichen die Genauigkeit eines stets wachsamen Prüfers – ohne dessen Grenzen bei Aufmerksamkeit und Konzentration. Ihre Leistung hängt jedoch maßgeblich von der Qualität der Trainingsdaten ab. Prof. Dr. Alexander Ecker, Mitgründer von Maddox AI, bringt es auf den Punkt: „Das beste KI-Modell kann nicht zaubern, wenn es auf einer inkonsistenten Datenbasis trainiert wurde. Die Qualität der Datenbasis, mit der KI-Modelle trainiert werden, ist der offensichtlichste, aber auch der am meisten ignorierte Hebel, um hochakkurate KI-Modelle in der visuellen Qualitätskontrolle zu entwickeln.“
In der Anlernphase markieren menschliche Experten Fehler auf Bauteilbildern und definieren so, welche Abweichungen als echte Defekte gelten (z. B. Kratzer, Schlagstellen) und welche ignoriert werden können (z. B. Schmutz, Schmierstoffe). Diese Annotationen bilden die Trainingsgrundlage für das KI-System. Damit bleibt der Mensch ein kritischer Faktor – und mit ihm auch die bekannten Probleme wie Subjektivität und Inkonsistenz. Behar Veliqi, Mitgründer und CTO von Maddox AI, betont: „Wenn ein Prüfer beim Annotieren einen Kratzer erkennt und markiert, während ein anderer Qualitätsmitarbeiter dies nicht tut, dann ist es unmöglich zu sagen, was für das KI-System gelten soll.“ Selbst das beste KI-System bleibt wirkungslos, wenn die Datengrundlage widersprüchlich ist.
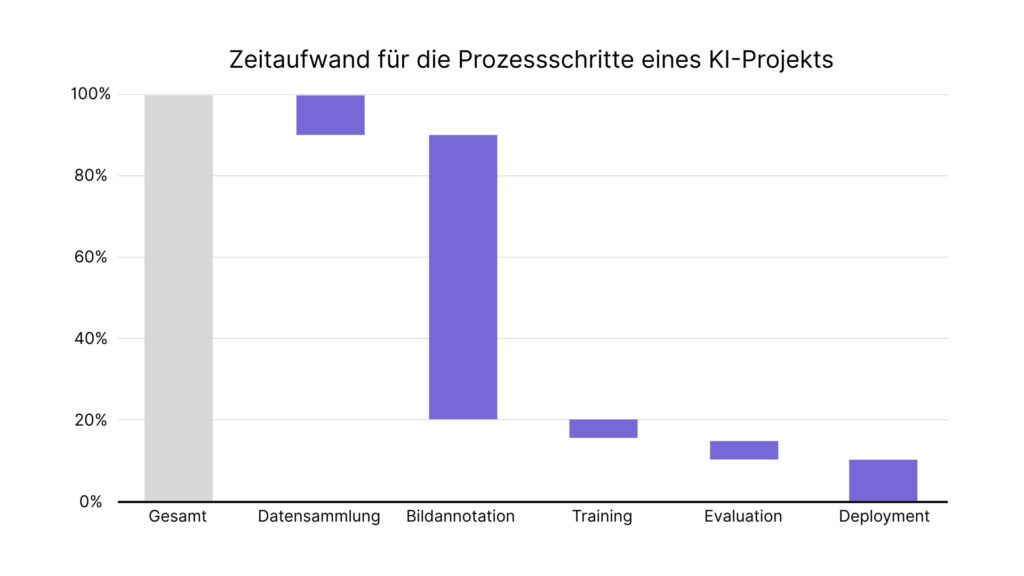
Neben der Anfälligkeit für subjektive Fehler ist die Annotation zugleich der zeitintensivste Teil eines KI-Projekts. Da dieser Schritt immer menschliche Expertise erfordert, lässt er sich weder vollständig automatisieren noch beliebig beschleunigen. Jedes Bild muss durch einen geschulten Prüfer betrachtet, bewertet und markiert werden. Damit bildet die Annotation den Engpass im Projektgeschäft: Sie ist der kritischste Faktor für die spätere Modellqualität und zugleich der größte Treiber von Zeit- und Kostenaufwand.
Produktisierung ist
die eigentliche Hürde
Neue Technologien oder Ansätze beginnen in Unternehmen meist mit Machbarkeitsanalysen. Erst wenn diese erfolgreich abgeschlossen sind, wird die Implementierung in der Live-Produktion angestrebt und versucht, die Lösung schrittweise zu skalieren. Doch ein erfolgreiches Pilotprojekt darf nicht mit einer dauerhaft funktionierenden Vision-Software verwechselt werden.
Um Bilderkennungsprobleme nachhaltig und skalierbar zu lösen, reicht ein leistungsfähiger Algorithmus allein nicht aus. Die eigentliche KI-Programmierung macht in der Regel weniger als 5% der Gesamtlösung aus. Der Hauptaufwand liegt im Aufbau eines vollständigen Ökosystems mit Tools für Datenannotation, Qualitätssicherung, Monitoring, Versionierung, automatisiertes Deployment und kontinuierliche Modellverbesserung im laufenden Betrieb. Erst diese Infrastruktur ermöglicht, dass ein KI-System robust, wartbar und langfristig nutzbar bleibt. Gerade hier scheitern aber viele Eigenentwicklungen großer Unternehmen. Zwar gelingt es häufig, in einem Pilotprojekt eine funktionierende Inspektionslösung zu demonstrieren, doch beim Übergang in den Regelbetrieb fehlen die Prozesse und Tools, um Daten konsistent zu annotieren, Modelle zu überwachen oder Fehler systematisch nachzuverfolgen. Ohne diese Basis entsteht keine nachhaltige Lösung, sondern ein einmaliger Prototyp, der im Praxisalltag schnell an seine Grenzen stößt.
Tooling für eine
konsistente Datenbasis

















